At the end of the blog I wrote about OMR competitions a couple of months ago, I mentioned that a prerequisite is automated evaluations.
Last two months I familiarized myself with the topic using the excellent paper ‘Towards a Standard Testbed for Optical Music Recognition’ by Donald Byrd and Jakob Grue Simonsen, and the OMRTestSuite (a set of 34 pages) that is referenced in the paper. (I would like to thank both authors for providing access to the data, and answering questions about them.)
As expected, I first discovered the depth of my ignorance. I did not know the difference between a mordent and a turn, or how one represents artificial harmonics, and only now begin to discover the difference between a spiccato and a staccatissimo. And don’t get me started on doit, falloff, plop, and scoop…
Susan A. Amrose referred to evaluations in her 2010 book ‘How Learning Works’ as “giving final judgment or evaluation of proficiency, such as grades or scores”. Furthermore, it is “about specific aspects of performance relative to specific target criteria”. I believe that there are a number of target areas in OMR where automated formative feedback or assessment are possible.
To start with an obvious example: if there is ground truth for a score in the form of a MusicXML representation, and an OMR system produces a MusicXML output, I can extract everything related to notes (including pitch, duration, chords, grace notes) and rests from the ground truth and compare it to the output by parsing/extracting the relevant information from the MusicXML. The same seems to be true for clefs, key signatures, time signatures, bar lines, articulations, dynamics etc.
So I started to create symbolic representations of the above mentioned OMRTestSuite. This was not easy but had the benefits of forcing me to look at literally everything.
Some impressions of working with results of commercial OMR products:
- I do not recall many instances of correcting the pitch of note. Much more frequently there were clusters of errors, where it was easier to delete a complete measure and re-enter it.
- Slurs and staccatos are different – I seem to recall correcting a bunch of them.
- Notation software in my view does not support editing well. It is much more geared to sequential entry. That is understandable, but why not support editing as another use case?
- Chords seem easier than multiple voices.
Based on this, I have formed some strong (but still weakly held) opinions about an OMR assessment system:
- Meaningful automated OMR assessments are possible.
- A substantial number of assessments will be necessary.
- For the definition of assessment community involvement is necessary – without acceptance and involvement of different stakeholders, this will ultimately not be successful.
- Multiple assessments can be used to calculate scores. The likelihood that there will be many ways to calculate scores is high, and that is a good thing.
Now let me present some results. For this, I used the MusicXML representation of two scores from the OMRTestSuite, and the output of three commercial OMR systems using an XML parser that extracted information about notes and rest as described above.
A very simple metric (count the number of notes by measure and duration) and compare it to the ground truth yields the following results:
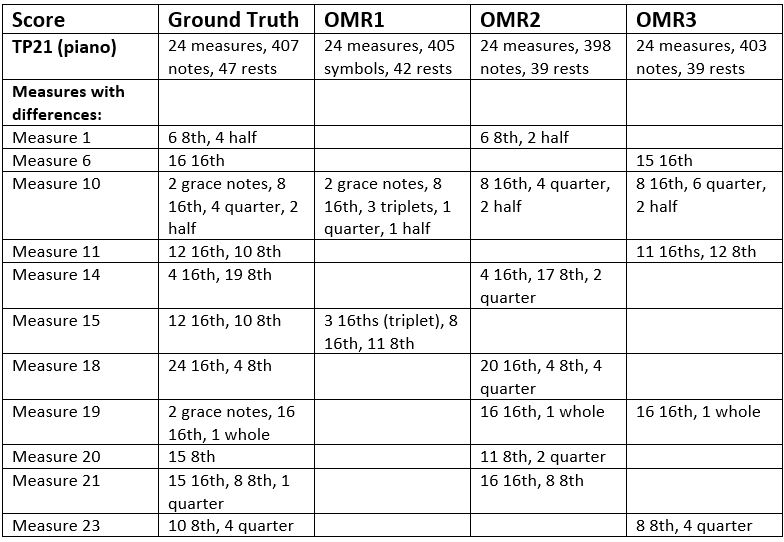
From this table, we conclude that:
- OMR1 did really well and tripped up only in situations that the other products had no issue with.
- The only reason measure 10 and 19 show up for OMR2 and OMR3 is the inability to handle grace notes.
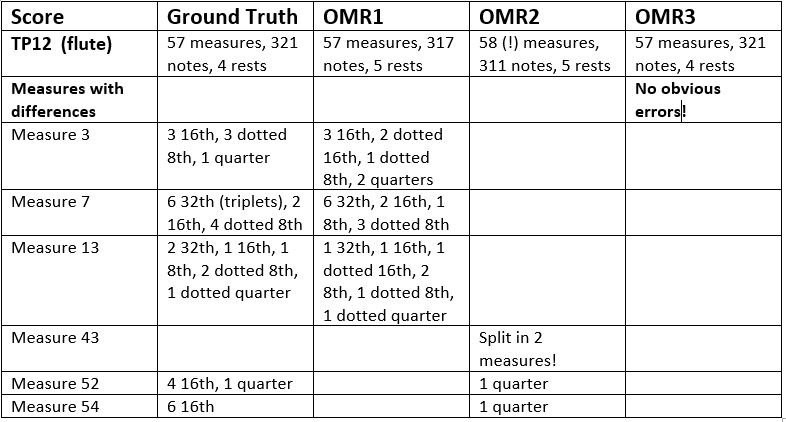
From this table, we see that OMR2 is perfect for 54 out of 57 measures and handles difficult measures well (e.g. where OMR1 slipped). Where it slips though, it slips really badly: splitting a measure 43 which is very similar to measure 41, and in measure 52 finding 1 note where there are 5 or 6 in the case of measure 54.
Now, this is a very simple assessment, and by no means complete. The advantage is that with very little effort I was able to identify problems without any false positives: if the number of notes in a measure is incorrect, something is definitely wrong, and one can point to the exact place where the problem is. It does not mean that all the notes have the right pitch.
As Donald and Jakob showed, OMR evaluations are difficult, and they will remain difficult. On the other hand: automation can be a good friend, and automated assessments may enable things like competitions! So my current answer to the title of this blog is yes, but there is a lot of work that needs to be done, and it will require involvement by the OMR community.
My next steps:
- I plan to create an automated assessment for slurs, staccatos and some more articulations.
- To run the assessment still involves some manual steps which I will automate.
- With multiple voices, hidden rests are currently not handled correctly.
I would love comments and feedback!

3 Comments Add yours