When I wrote the first blog post about assessments about a month ago, I noted that OMR products had trouble with slurs and articulations. So an assessment of both seems very useful!
Let us have a look at the following stave:

One of the OMR outputs looked like this:

The assessment is fairly straight-forward: a slur is defined by its beginning note and the end note. So when comparing the results between ground truth and OMR for any slur, the result can be that both beginning and end note match, and either beginning note or end note are different, or that there is not match. The second case would be counted at ‘partially correct’.
Here is the detailed output of the assessment tool for the stave comparison above:

For the whole page the output looks like this:
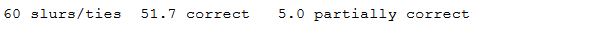
My remark a months ago correlates with the findings so far: the accuracy rate for the recognition of slurs/ties is substantially lower than for notes/rests. There are substantial difference between the OMR products, though.
Here is the list of articulations and ornaments that are included in the assessment: staccato, tenuto, accent, breath-mark, trill-mark, staccatissimo, fermata.
In last weeks post about assessment with MusicXML we used an example with lots of articulations. Let us have a look again:

The output of an OMR for the stave looks like this:

The assessment result:

So the OMR missed the breath-mark in the first measure and staccato in the fourth measure. As for breath-marks: none of the OMR products I have looked at handle them.
The results for the whole page:

What means ‘partially correct’? It means that the OMR recognized a type of articulation/ornament, but the ground truth expected something else. For example, where a ‘staccato’ was recognized by the OMR, but the ground truth contained a ‘staccatissimo’. That persuaded me to count the mere detection of an articulation as ‘partially correct’. Lately, I seem to see more case of a ‘tenuto’ instead of a ‘staccato’, and no, I do not think that this is partially correct. I’ll wait for more results!
