In the last weeks, I have shown how a note/rest assessment works for OMR systems that supports MusicXML as an output. There are of course OMR systems in development that do not support MusicXML and may not be able to process a full page. How can the note/rest assessment handle such situations?
To address this, a common strategy is to split the page into separate stave images like this:

Using the monophonic agnostic model by Jorge Calvo Zaragoza and David Rizo produced the following output for the first 5 measures:
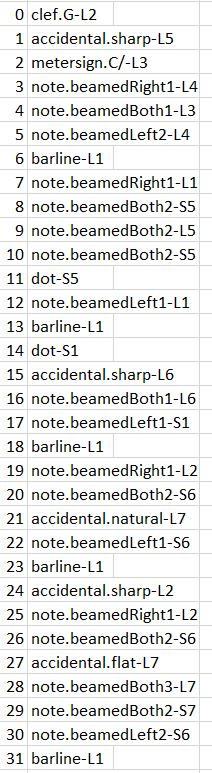
To do the comparison, the note/rest assessment tool uses a fairly simple data structure for monophonic scores, consisting of (measure – type (note/rest) – accidental – staff position – duration – duration type (16th, 8th..) – no of dots). (Here is why ‘duration’ is needed: a 16th duration is 0.25. If it is a dotted 16th, the ‘number of dots’ is be 1, and ‘duration’ is 0.375. If the 16th is part of a triplet, the ‘duration’ would be 0.1666667. )
So what needed to be done was the mapping of the output above to this data structure. This was done in about 200 lines of not-so-pretty Python code.
This allowed a detailed comparison to be run. The image shows the results for the 5 measures shown above:
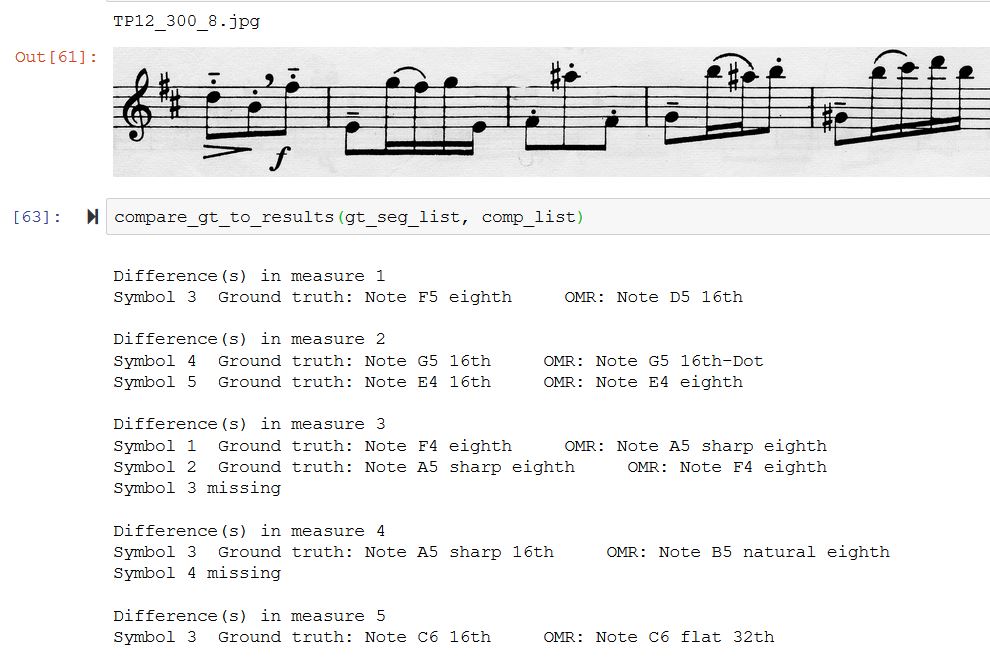
Looking at measure three, the model recognized the first note (F4 staccato) as a ‘Dot.S1’, not a note. The mapping software ignored this. The second and third notes were actually recognized correctly but interpreted as the first and second note.
Two other examples:
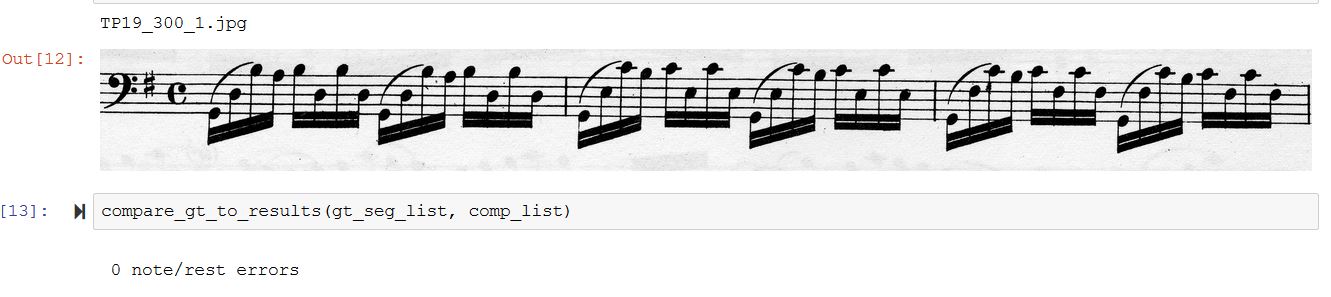
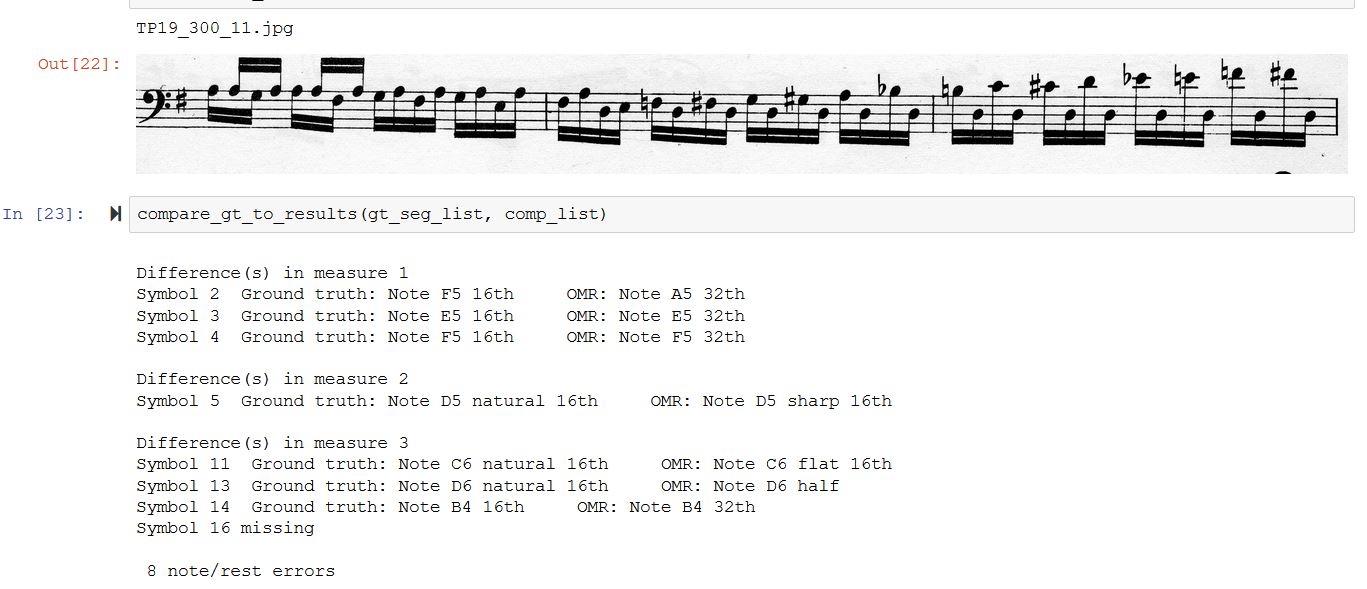
Once the mapping of the results of an OMR system to what the note/assessment tool expect is done, it is very easy to produce assessments for additional stave images.
Getting access to assessments would be substantially simplified if the OMR community would agree on a common core for OMR outputs!
Thanks to Jorge Calvo Zaragoza for giving me access to the model, and for the help splitting the images!

I don’t quite understand the paragraph about the data structure. Are these tuples for each element with all of that properties? What is a non-“real” duration? The flag/beam by which it is notated? If yes, is that relevant? And by “no of dots” are you referring to “number of dots”? Could you elaborate on this paragraph, please?
LikeLike
The answer to the first question is ‘yes’ (I think).
For duration we have duration type – say it is a ’16th’. Normally the duration is 0.25. However if it is a dotted 16th, the ‘number of dots’ would be 1, and the ‘duration’ would be 0.375.
For a 16th as part of a triplet the ‘duration’ would be 0.1666667.
LikeLike